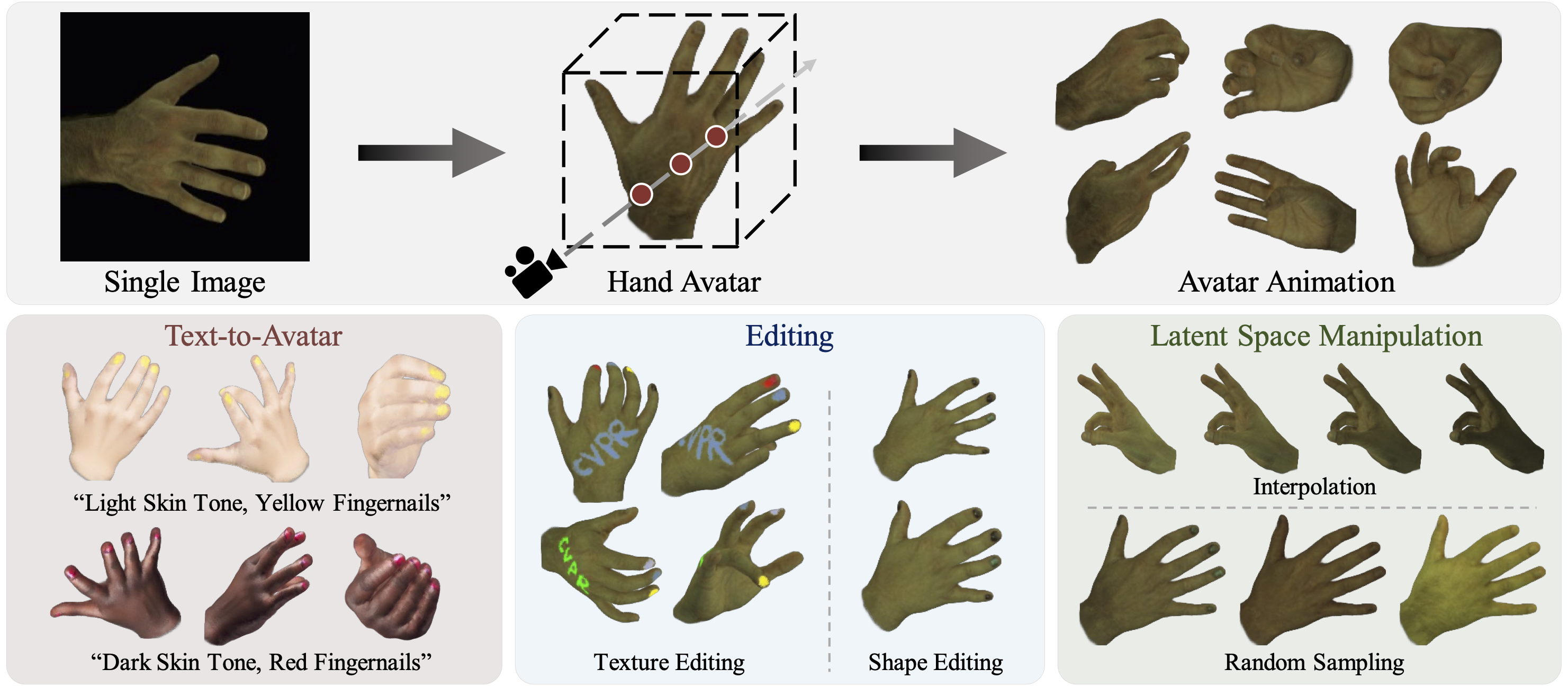
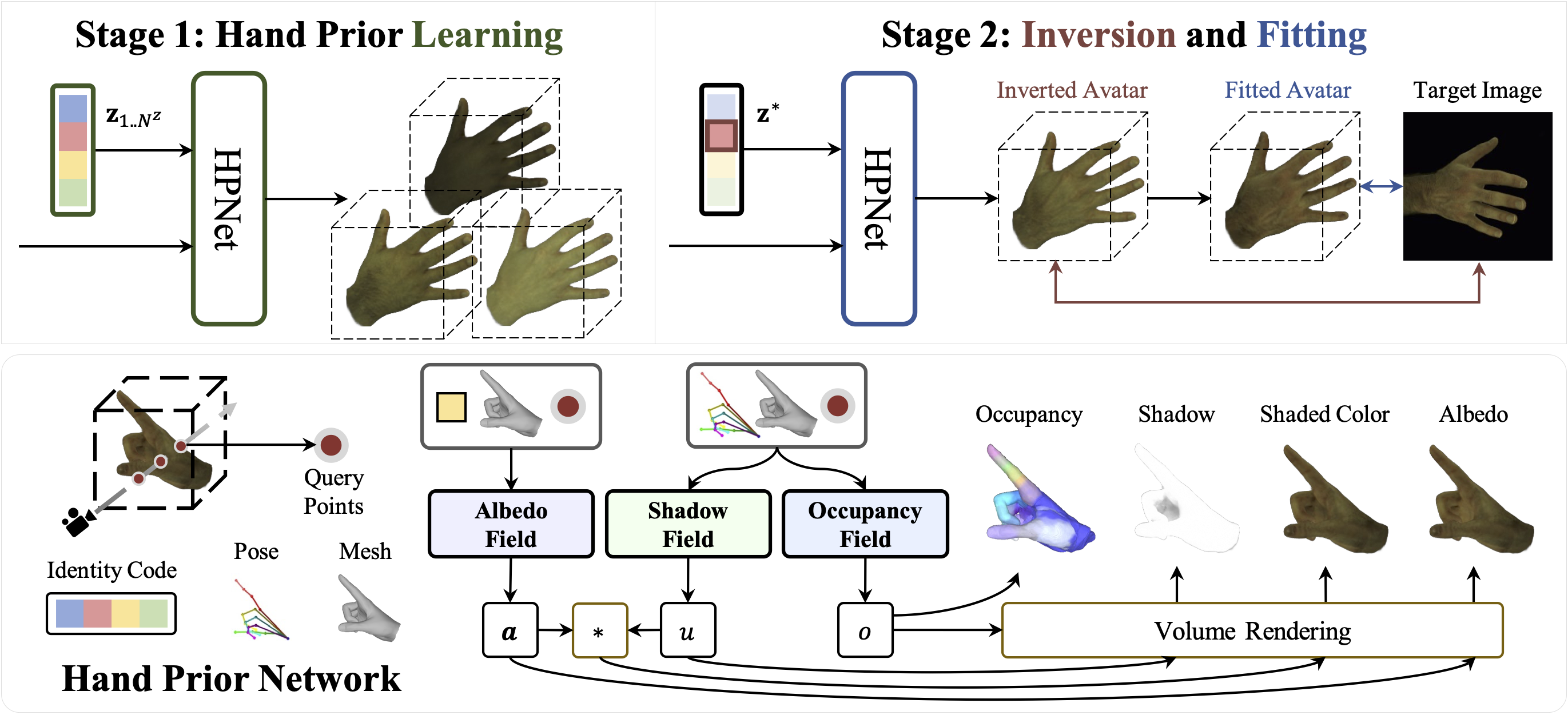
In this paper, we delve into the creation of one-shot hand avatars, attaining high-fidelity and drivable hand representations swiftly from a single image. With the burgeoning domains of the digital human, the need for quick and personalized hand avatar creation has become increasingly critical. Existing techniques typically require extensive input data and may prove cumbersome or even impractical in certain scenarios. To enhance accessibility, we present a novel method OHTA (One-shot Hand avaTAr) that enables the creation of detailed hand avatars from merely one image. OHTA tackles the inherent difficulties of this data-limited problem by learning and utilizing data-driven hand priors. Specifically, we design a hand prior model initially employed for 1) learning various hand priors with available data and subsequently for 2) the inversion and fitting of the target identity with prior knowledge. OHTA demonstrates the capability to create high-fidelity hand avatars with consistent animatable quality, solely relying on a single image. Furthermore, we illustrate the versatility of OHTA through diverse applications, encompassing text-to-avatar conversion, hand editing, and identity latent space manipulation.





@inproceedings{zheng2024ohta,
title={OHTA: One-shot Hand Avatar via Data-driven Implicit Priors},
author={Zheng, Xiaozheng and Wen, Chao and Su, Zhuo and Xu, Zeran and Li, Zhaohu and Zhao, Yang and Xue, Zhou},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}}